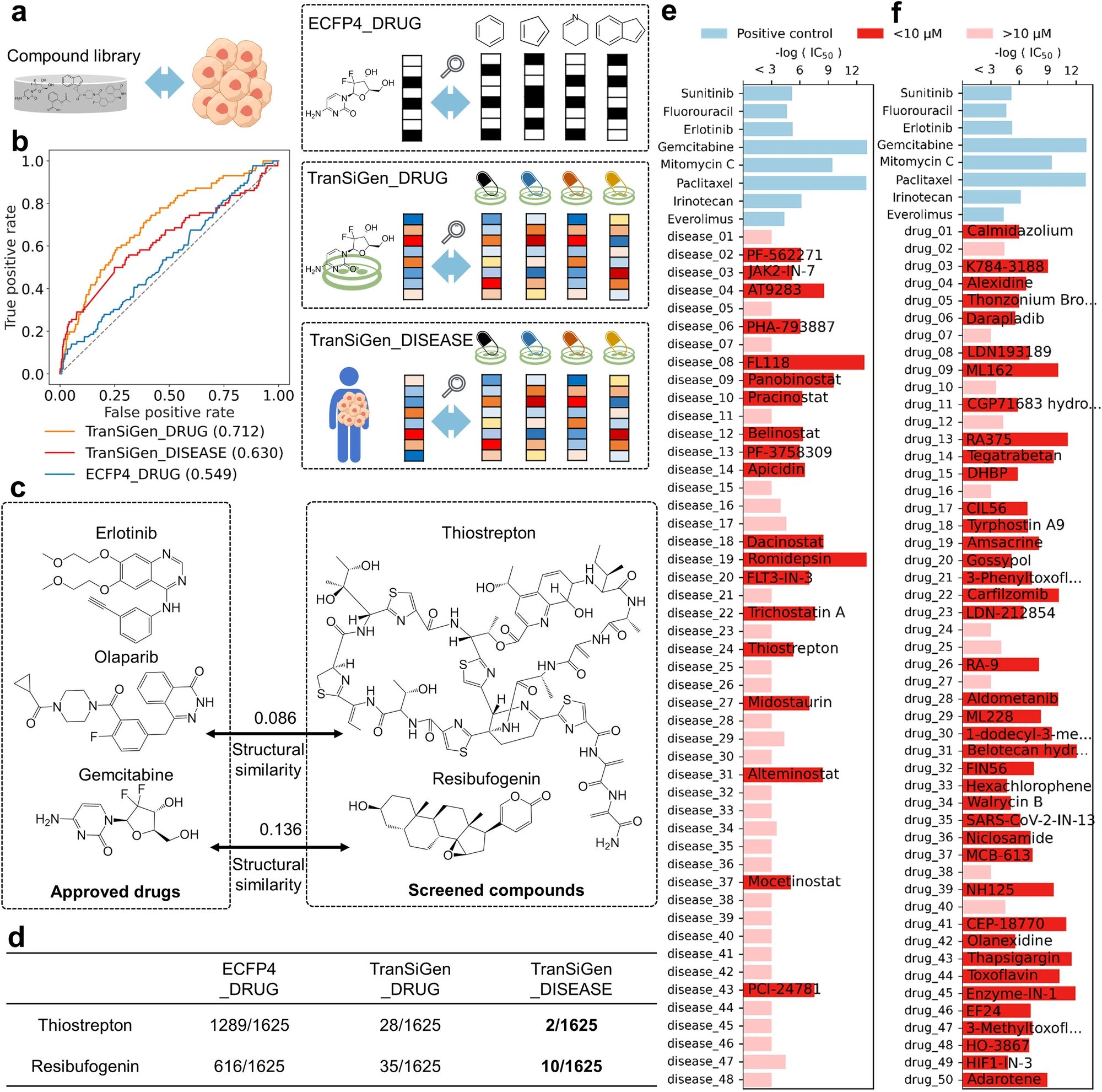
中国科学院上海药物研究所的郑明月团队于2024年6月25日在《Nature Communications》杂志上发表了一篇研究论文,题为“深度表征学习在化学诱导的转录谱中用于基于表型的药物发现”。该团队认为,将TranSiGen应用于药物研发中,对于推动生物医学领域具有重要的前景。TransiGen能够分析基底细胞基因表达和分子结构,从而高精度地重建化学诱导的转录谱。通过捕捉细胞和化合物信息,TransiGen衍生的特性在多种下游任务中表现出疗效,比如基于配体的虚拟筛选、药物反应预测和基于表型的药物再利用。值得注意的是,TransiGen在胰腺癌药物研发中的应用显示出其识别有效化合物的潜力。01 背景研究正在药物研发领域中,人工智能(AI)正在推动一场革新。虽然长期以来基于靶点的方法一直是该领域的主流,但这种方法的局限性,如缺乏明确的靶点、脱靶效应和治疗反馈不尽如人意,催生了基于表型的方法的兴起。这些方法特别注重对于候选药物的全面细胞反应,致力于提供更全面的疾病机制理解,并有可能揭示新的药物靶点和治疗途径。转录组学数据分析在药物研发和理解疾病机制方面扮演着非常重要的角色。通过捕捉不同生物学背景下的全球基因表达情况,它为我们提供了对细胞和生物状态的丰富见解。高通量RNA测序(RNA-seq)技术的推广使得我们可以生成大规模的基因表达图谱,这些图谱提供了有关细胞如何对不同破坏做出反应的宝贵信息。对这些特征的深入探索对于药物研发起着核心作用,有助于阐明药物的作用机制(MOA)。然而,直接利用监督学习模型拟合基因表达值可能面临困难,因为真正的扰动信号需要和混杂因素以及表达谱中的固有噪声相区分。为了克服这一限制并生成新的转录图谱,本研究提出了基于VAE的TranSiGen框架,该框架采用自监督学习降噪和重建转录图谱,进而推断新的图谱模型。TranSiGen同时学习三个关键分布:无扰动的基础分布、化学诱导的扰动分布以及它们之间的映射关系。自监督学习的方法有效减轻了数据中的噪声并揭示了潜在的扰动信号。该方法具有以下几个关键优势:(1)改进转录图谱的推断能力:与基线模型相比,TranSiGen在推断基础谱、化学扰动谱和相应的差异表达基因(DEG)方面具有卓越性能。(2)统一表示细胞和化合物特征:TranSiGen生成的扰动图谱有效地捕捉了细胞和化合物特征,这可以通过基于细胞系和药物MOA的可视化分析来证明。(3)在下游任务中具有多重功能:TranSiGen衍生的特征已被证明在各种任务中发挥了有效的作用,包括基于配体的虚拟筛选、药物反应预测和基于表型的药物再利用。TranSiGen基于表型的方法在筛选胰腺癌化合物方面有着卓越的表现,随后的体外验证结果证实了其高命中率。这表明TranSiGen具有强大的识别有效化合物的能力。值得注意的是,将TranSiGen与基于表型的药物研发管线整合,有望显著提高研发效率并降低成本。02 科研成果发展利用药物再利用来治疗胰腺癌的方式是基于表型特征。将化学引发的基因转录谱与疾病联系起来,可以帮助找出治疗特定疾病的潜在化合物。利用TranSiGen技术获得的基因转录谱,可与经过化学处理和未经处理的疾病状态的谱结合,用于筛选治疗疾病的候选化合物。本研究团队将TranSiGen融入基于表型的胰腺癌药物再利用管线,以评估其在PRISM Reutilposing数据集的1,625种化合物库中,筛选出优先的YAPC胰腺癌细胞系敏感化合物的能力。研究团队采用了两种基于表型的策略,并将其与传统的基于结构相似性的方案进行了比较。TranSiGen_DRUG使用已批准的胰腺癌药物的真实差异表达基因,以识别具有类似扰动效应的化合物。相反,TranSiGen_DISEASE寻找可逆转胰腺癌差异表达基因的化合物。以下是三种方法的筛选性能图表。ECFP4_DRUG 的预测分类性能最低,TranSiGen_DISEASE 次之,而 TranSiGen_DRUG 则表现最佳。值得一提的是,TranSiGen_DISEASE 方法无需任何化学特征描述符,在模拟缺少已知治疗药物的疾病场景中表现良好。这是一种基于结构相似性的策略,无法解决的挑战。总的来说,TranSiGen 扩展了可以通过预测扰动曲线进行筛选的化合物范围。它可以轻松地集成到基于表型的药物再利用管道中,从而提高药物研发效率,并最大限度地降低成本。03 研究的结论本研究表明,TranSiGen在推断基因表达剖面、化学诱导的扰动剖面和相应的DEG方面优于现有的模型。这一功能可扩展和增强现有药物研发数据集,并开辟了新的途径。TranSiGen的核心优势在于其能够克服基因表达谱中固有的干扰和混杂因素,提供一种标准化的方法来表征与细胞背景和化合物效应相关的表型信息。这种标准化有助于集成和提高各种下游任务的效率,包括基于配体的虚拟筛选、药物反应预测和基于表型的药物再利用。值得注意的是,TranSiGen在基于表型的胰腺癌药物再利用以及随后的体外验证中展现了其在真实世界药物研发场景中的前景。TranSiGen团队在药物研发领域一直在探索基于VAE模型和自监督学习方法,为其打下了坚实的基础。未来,团队将致力于解决TranSiGen中来自不同来源数据的异质性问题,增强模型的泛化能力以拓宽其应用领域。此外,团队计划将之前的生物学知识(如通路和基因本体)整合到模型中,以提高其精度和可解释性。除了药物研发,团队还计划研究TranSiGen在精准医学和疾病建模方面的潜在作用,并揭示这些领域的巨大前景。该领域的最终目标是建立一个全面的框架,以有效利用高维基因表达数据,从而加速药物研发并揭示疾病机制的复杂性。TranSiGen凭借其独特的优势和可扩展性,向实现这一目标迈出了宝贵的一步。